AutomatonChecker configuration files
Background
AutomatonChecker is based on an idea that several types of properties which must or needn't hold in the program can be described by finite automata. Consider for example a module, which implements functions lock() and unlock() with an assumption, that these functions must always be called in pair (lock()...unlock()). Thus this function contains a bug:
void foo()
{
lock();
...
if (...)
return; /* !error: unlock() not called! */
...
unlock();
}
AutomatonChecker can be used to detect all such errors by providing it a finite automaton which defines the property. In this particular case, that functions lock() and unlock() always must be called in pair. The automaton for this property can be designed as follows:
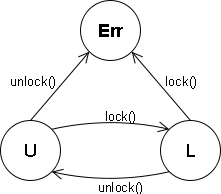
When AutomatonChecker is given this automaton, then it searches all the paths in the source program and checks if in some path the automaton's error state is reached. If this is the case, then AutomatonChecker reports an appropriate error message.
AutomatonChecker expects finite automata to be stored in XML files. Description of of these XML files can be found in the next section.
XML file organization
Example from the previous section can be expressed in an AutomatonChecker XML file as depicted here:
<?xml version="1.0" encoding="UTF-8" ?>
<automaton>
<!-- Section: Automaton textual description -->
<description name="lock/unlock"
desc="lock()...unlock() pair matching detector"/>
<!-- Section: Defining automaton's start state -->
<start state="U"/> <!-- here state called 'U' is chosen to be a start state -->
<!-- Section: Automaton's transitions between regular states -->
<transition from="U[A]" by="lck[A]" to="L[A]" />
<transition from="L[A]" by="ulck[A]" to="U[A]" />
<!-- Section: Automaton's transitions from regular states into error state -->
<error from="U[A]" by="ulck[A]"
desc="double unlock"
level="0"
entry="The function called in unlocked state."
begin="The lock is unlocked here."
propag="not affected == the lock is still unlocked."
end="The lock is unlocked and here is an attempt to unlock it twice."/>
<error from="L[A]" by="lck[A]"
desc="double lock"
level="0"
entry="The function called in locked state."
begin="The lock is locked here."
propag="not affected == the lock is still locked."
end="The lock is locked and here is an attempt to lock it twice."/>
<!-- Section: XML patterns -->
<pattern name="lck">
<functionCall>
<id>lock</id>
</functionCall>
</pattern>
<pattern name="ulck">
<functionCall>
<id>unlock</id>
</functionCall>
</pattern>
</automaton>
In the presented example there are five section commentaries which splits whole definition into semantically different parts of the file. Those commentaries have only one reason in this text – to highlight semantically different parts. AutomatonChecker will ignore them while reading the file.
In the following text there is a description of all parts of the XML file:
Section 1: Automaton textual description
Description consists of automaton name specification and textual description of an automaton purpose. Both name and textual description may contain any user defined text.
Section 2: Defining automaton's start state
When AutomatonChecker is about to start checking the source code, then it necessarily needs to know in what automaton state it should start. So the user must specify one of the regular states of the automaton as a start state.
Section 3: Automaton transitions among regular states
An automaton transition between two regular states is represented as an arrow from the source state to the target state. This arrow is labeled by the name of an XML pattern (see later). The pattern defines a source code construct pattern, which must match to the code fragment currently being checked by the AutomatonChecker. If the pattern is mached, then the transition is performed.
There are special marks of form '[A]' in all the attributes of the transition rule definition. We can ignore them for now. Their purpose will be explained at the end of the tutorial.
Section 4: Automaton transitions from regular states into the error state
The automaton's error rule is represented by an arrow from a regular state to the error state. The arrow is labeled by the name of an XML pattern (see later) in the same manner as above. The error state is only one in any automaton, thus it need not be specified (coze? chybi tam "multiple times"?).
Special marks of form '[A]' are allowed as well.
Section 5: XML patterns
XML patterns define templates in form of AST, which are supposed to match some source code fragments. One such syntactic fragment is a call to a function. In our example, both patterns represent function call templates. The first pattern in the file has name 'lck'. It will match any call expression in the checked source code, where the name of a called function exactly matches identifier enclosed inside <id></id> element. In our case the identifier is 'lock'.
See separate tutorial describing XML pattern for more details.
Special marks of form '[X]' in transitions
In general, one XML pattern may match whole set of expressions in the source file, and not exactly one concrete expression like in our example. Thus for each such pattern match, the AutomatonChecker must create whole new automaton instance and trace through the source code. Consider for example, that our functions lock and unlock accept one parameter. Then we should be able to check also this code:
struct lock a;
struct lock b;
void foo()
{
lock(a);
lock(b);
unlock(b);
unlock(a);
}
In this example the pattern lck would be defined as follows (again, for more info see XML pattern tutorial):
<pattern name="lck">
<functionCall>
<id>lock</id>
<var name="P1"/>
</functionCall>
</pattern>
Now, the pattern lck matches both expression lock(a) and lock(b). If the AutomatonChecker treated both matches in one automaton, then it would report a double lock error, which is incorrect. Thus the AutomatonChecker creates two instances of defined automaton, where first instance is related to match P1~a, the second is related to match P1~b.
An expression of form [X] in transitions is used to express relations among different automata instances. X is a variable name ranging over automata instances.
Here are examples of transitions with their meanings described underneath:
-
<transition from="U[A]" by="lck[A]" to="L[A]" />
A transition from state U of automaton instance A by pattern lck which matches only A-related code fragments, to state U of automaton instance A. -
<transition from="U[A]" by="lck[B]" to="L[A]" />
A transition from state U of automaton instance A by pattern lck which matches only B-related code fragments, where A and B are different instances of automaton, to state U of automaton instance A. -
<transition from="L[A]" by="lck[B]" to="LL[A][B]" />
A transition from state U of automaton instance A by pattern lck which matches only B-related code fragments, where A and B are different instances of automaton, to state LL of pair of automaton instances A and B. This pair of instances represents multiplication of both automata.